Getting started
Texthero from zero to hero.
Texthero is a python package to let you work efficiently and quickly with text data. You can think of texhero as scikit-learn for text-based dataset.
Overview
Given a dataset with structured data, it's easy to have a quick understanding of the underlying data. Oppositely, given a dataset composed of text-only, it's harder to have a quick undertanding of the data. Texthero help you there, providing utility functions to quickly clean the text data, tokenize it, map it into a vector space and gather from it primary insights.
Pandas integration
One of the main pillar of texthero is that is designed from the ground-up to work with Pandas Dataframe and Series.
Most of texthero's methods simply apply a transformation to a Pandas Series. As a rule of thumb, the first argument and the ouput of almost all texthero methods are either a Pandas Series or a Pandas DataFrame.
Pipeline
The first phase of almost any natural language processing is almost the same, independently to the specific task.
Pandas introduced Pipe function starting from version 0.16.2. Pipe enables user-defined methods in method chains
Installation and import
Texthero is available on pip. To install it open a terminal and execute
pip install texthero
If you have already installed it and want to upgrade to the last version type:
pip install texthero -U
Getting started
For a simple example we make use of the BBC Sport Dataset, it consists of 737 documents from the BBC Sport website corresponding to sports news articles in five topical areas from 2004-2005.
The five different areas are athletics, cricket, football, rugby and tennis.
The original dataset comes as a zip files with five different folder containing the article as text data for each topic.
For convenience, we created this script simply read all text data and store it into a Pandas Dataframe.
Import texthero and pandas.
import texthero as hero
import pandas as pd
Load the bbc sport dataset in a Pandas DataFrame.
df = pd.read_csv(
"https://github.com/jbesomi/texthero/raw/master/dataset/bbcsport.csv"
)
>>> df.head(2)
text topic
0 "Claxton hunting first major medal\n\nBritish h..." athletics
1 "O'Sullivan could run in Worlds\n\nSonia O'Sull..." athletics
Preprocessing
Clean
To clean the text data all we have to do is:
df['clean_text'] = hero.clean(df['text'])
Recently, Pandas has introduced the pipe function. You can achieve the same results with
df['clean_text'] = df['text'].pipe(hero.clean)
Tips. When we need to define a new column returned from a function, we prepend the name of the function to the column name. Example: df['tsne_col'] = df['col'].pipe(hero.tsne). This keep the code simple to read and allows us to construct complex pipelines.
The default pipeline for the clean method is the following:
fillna(s)Replace not assigned values with empty spaces.lowercase(s)Lowercase all text.remove_digits()Remove all blocks of digits.remove_punctuation()Remove all string.punctuation (!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~).remove_diacritics()Remove all accents from strings.remove_stopwords()Remove all stop words.remove_whitespace()Remove all white space between words.
As texthero is still in beta, the default pipeline may undergo some minor changes in the next versions.
Custom pipeline
We can also pass a custom pipeline as argument to clean
from texthero import preprocessing
custom_pipeline = [preprocessing.fillna,
preprocessing.lowercase,
preprocessing.remove_whitespace]
df['clean_text'] = hero.clean(df['text'], custom_pipeline)
or alternatively
df['clean_text'] = df['clean_text'].pipe(hero.clean, custom_pipeline)
Tokenize
Next, we usually want to tokenize the text (tokenizing means splitting sentences/documents into separate words, the tokens). Of course, texthero provides an easy function for that!
df['tokenized_text'] = hero.tokenize(df['clean_text'])
Preprocessing API
The complete preprocessing API can be found here: api preprocessing.
Representation
Once the data is cleaned and tokenized, the next natural step is to map each document to a vector so we can compare documents with mathematical methods to derive insights.
TFIDF representation
TFIDF is a formula to calculate the relative importance of the words in a document, taking into account the words' occurrences in other documents.
df['tfidf'] = hero.tfidf(df['tokenized_text'])
Now, we have calculated a vector for each document that tells us what words are characteristic for the document. Usually, documents about similar topics use similar terms, so their tfidf-vectors will be similar too.
Dimensionality reduction with PCA
We now want to visualize the data. However, the tfidf-vectors are very high-dimensional (i.e. every document might have a tfidf-vector of length 100). Visualizing 100 dimensions is hard!
Thus, we perform dimensionality reduction (generating vectors with fewer entries from vectors with many entries). For that, we can use PCA. PCA generates new vectors from the tfidf representation that showcase the differences among the documents most strongly in fewer dimensions, often 2 or 3.
df['pca'] = hero.pca(df['tfidf'])
All in one step
We can achieve all the steps shown above, cleaning, tokenizing, tf-idf representation and dimensionality reduction in a single step. Isn't that fabulous?
df['pca'] = (
df['text']
.pipe(hero.clean)
.pipe(hero.tokenize)
.pipe(hero.tfidf)
.pipe(hero.pca)
)
Representation API
The complete representation module API can be found here: api representation.
Visualization
texthero.visualization provide some helpers functions to visualize the transformed Dataframe. All visualization utilize under the hoods the Plotly Python Open Source Graphing Library.
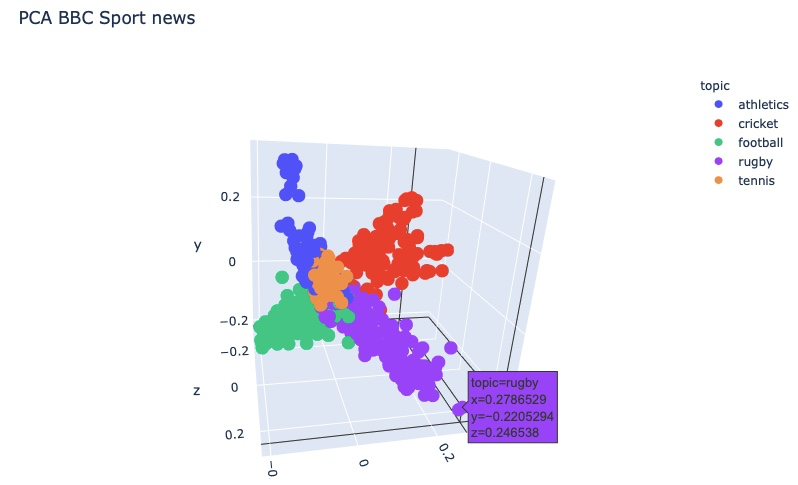
hero.scatterplot(df, col='pca', color='topic', title="PCA BBC Sport news")

Also, we can "visualize" the most common words for each topic with top_words
NUM_TOP_WORDS = 5
df.groupby('topic')['clean_text'].apply(lambda x: hero.top_words(x, normalize=True)[:NUM_TOP_WORDS])
topic
athletics said 0.010330
world 0.009132
year 0.009075
olympic 0.007819
race 0.006392
cricket test 0.008492
england 0.008235
first 0.008016
cricket 0.007906
one 0.007760
football said 0.009709
chelsea 0.006234
game 0.006071
would 0.005866
club 0.005601
rugby england 0.012833
said 0.008512
wales 0.008025
ireland 0.007440
rugby 0.007245
tennis said 0.013993
open 0.010575
first 0.009608
set 0.009028
year 0.008447
Name: clean_text, dtype: float64
Visualization API
The complete visualization module API can be found here: api visualization.
Summary
We saw how in just a couple of lines of code we can represent and visualize any text dataset. We went from knowing nothing regarding the dataset to see that there are 5 (quite) distinct areas representig each topic. We went from zero to hero.
import texthero as hero
import pandas as pd
df = pd.read_csv(
"https://github.com/jbesomi/texthero/raw/master/dataset/bbcsport.csv"
)
df['pca'] = (
df['text']
.pipe(hero.clean)
.pipe(hero.tokenize)
.pipe(hero.tfidf)
.pipe(hero.pca, n_components=3)
)
hero.scatterplot(df, col='pca', color='topic', title="PCA BBC Sport news")
Next section
By now, you should have understood the main building blocks of texthero.
In the next sections, we will review each module, see how we can tune the default settings and we will show other applications where Texthero might come in handy.